If you are more used to using doocs servers and/or interfacing with them using doocs clients than using TINE server and clients, then you may encounter impedance mismatches concerning expected systematics or otherwise be unaware of setup configuration parameters which could make life easier.
We will try to address some of the most common questions and issues below.
- Note
- This page is a work in progress.
Some Rules about Names
The DOOCS naming hierarchy follows the pattern facility / device / location / property. At first glance this appears to be a good match to the TINE naming hierarchy, which follows the pattern /context/server/device[property], with the notable points of possible confusion. i.e. what DOOCS calls a device is what TINE calls a server. And what DOOCS calls a location is what TINE calls a device.
The DOOCS facility maps to the TINE context, with a caveat (discussed below) concerning the subsystem.
Both DOOCS and TINE refer to a property, which is a coverall term for an attribute, a method, or a command, i.e. something which can be called, and as a point of fact, is the purpose of the call. To this end, a TINE address key will likely enclose the property in brackets, as opposed to merely placing at the end of an address hierarchy with the '/' separator. However (please note!) most if not all TINE API calls which take a full address will also accept the address key with only '/' separators.
And about those slashes ('/') ? ...
The DOOCS APIs expect an address name to begin with facility, without a leading '/', and all addresses must be fully qualified, i.e. of the form facility/device/location/property. The TINE APIs on the other hand expect a fully qualified address name to begin with a leading '/', i.e. of the form /context/server/device[property] (or /context/server/device/property if you insist). This is in loose analogy with a unix file system file name, where the leading '/' indicates an absolute path. If you omit the leading '/', then the address specification is not fully qualified and the initial address name is taken to be a server name and the context is assumed to have been omitted, thereby signaling the TINE ENS to find this server independent of context. This will work if the server in fact exists in only a single context. If the same server name appears in multiple contexts (as for instance as the central alarm server CAS might), then such an incomplete address will result in the error: ambiguous. Otherwise it is occasionally useful to omit the context name in certain APIs.
Subsystems
And what about subsystems? A TINE Server will supply a subsystem category upon registration (if it doesn't it will be assigned to MISC - miscellaneous). The subsystem will not be part of the namespace, but can be used as a query criterion for browsing. That is fundamentally different in DOOCS, where no separate subsystem exists in any hierarchy. Instead DOOCS servers tend to decorate the facility with an associated subsystem.
For example, in TINE a server Modulators might register itself in context XFEL and with subsystem RF. The RF would not be part of the address name, when a client calls a property at the server. However RF can be used in any browser to provide a narrower list of relevant servers.
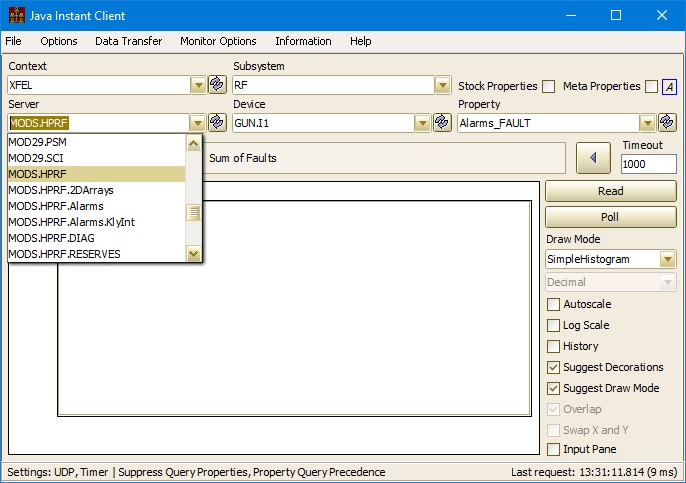
DOOCS on the other hand will register such a server in e.g. XFEL.RF. That is, it will claim that the facility is XFEL.RF and assume that anyone browsing the control system landscape will visually associate e.g. XFEL.RF and XFEL.MAG with the same accelerator (XFEL), although XFEL.RF, XFEL.MAG, and e.g. PETRA.MAG all formally have the same relevance, even though stopping a server in PETRA.MAG would not logically be expected to have an effect on XFEL operations, whereas stopping a server in XFEL.MAG would. The decoration does at least make it clear in the address which subsystem a server belongs to, if not already obvious from the server name.
In TINE the context relevance is important, as there are central services (i.e. running servers), whose identity is fixed by the context. No matter the subsystem, a server should know how to contact its central alarm server (CAS), state server, globals server, archive server, etc.
In light of this, a DOOCS server which registers via TINE with the TINE ENS with a subsystem decorated context will have the susbsytem decoration removed from the ENS context entry and assigned to the ENS subsystem entry.
As a convenience to unsuspecting DOOCS users who are determined to supply the decoration as part of the address in some API call, the TINE ENS will nonetheless correctly resolve the address as if the decoration were absent.
We should also note that some decorations are fully allowed. These are TEST (test servers not used in machine operation, e.g. REGAE.TEST), SIM (simulation servers not used in operations but otherwise designed to test communications e.g. FLASH.SIM), and EXT (external servers not used in machine operations but related to external access, e.g. PETRA.EXT).
- Note
- An underscore '_' contained in a context name is treated as equivalent to a '.'. In fact any underscore will be converted to a dot in both address registration and address resolution. You might ask yourself what the intended difference between e.g. PETRA.TEST and PETRA_TEST should be in the first place. But we point out here that there is no difference as far as TINE name resolution goes.
This creates the amusing dilemma of for example the DOOCS facility XFEL_SIM.RF being doubly decorated.
This will show up in TINE in the context XFEL.SIM and in subsystem RF.
Collisions
So ... this could lead to name collisions.
In general server developers should strive to provide their servers with meaningful names related to purpose and functionality. From a hardware engineer's point of view this, alas, might lead to such generic, not-particularly descriptive server names such as ADC. And it might further ensue that such generic, not-particularly descriptive servers show up in multiple decorated facilities, i.e. in XFEL.RF/ADC and in XFEL.DIAG/ADC, for instance.
Then you would have a problem if you simply turn on the TINE thread. As at the TINE ENS, if the .RF and the .DIAG are removed, then you would have two servers vying to become /XFEL/ADC in the TINE landscape (remember that the subsystem is not part of the namespace).
Such situations (if you really, really, really want to call your server ADC) can be overcome at the configuration level by assigning the DOOCS configuration parameter(s) SVR.TINESUFF (suffix to append to the server name) or SVR.TINEPREF (prefix to prepend to the server name, or both. If you'd like, you can put the subsystem back in by using the SVR.TINESUFF = .RF or .DIAG.
Case Sensitivity
All of the names registered in the TINE world are case-insensitive. What should be the difference between a device or property called TEST and one called Test ? And who could remember it anyway? Often, properties and devices are given names using camel case.
In any event, in a browser, you would see the name as it was registered, even though you're free to use the case you wish in making API calls.
In the DOOCS world on the other hand, names are case-sensitive and usually registered in ALL CAPS, making liberal use of underscores.
Browsing
So we have just noted that the address hierarchy in the DOOCS world is something like facility/device/location/property and in the TINE world something similar, /context/server/device[property].
The naming services will provide a list of known contexts in the control system and will also provide a list of known device servers in a given context. Unless the server in question is a group server (see below) any remaining browsing queries will be handled by the server itself. If the server is off-line then there is no way to ascertain the available devices and properties at the server (and it would be of minimal use to have such a list when the server is off-line!).
By and large a device server is a somewhat object-oriented control system entity providing an interface to instances of some particular kind of device, e.g. a beam position monitor (BPM), a magnet power supply controller (PSC), a vacuum pump, all of which have the same characteristics, or at least are made to look like they have the same characteristics. One could have PSC hardware from different vendors, which might differ in specific details, meaning that some device instances might have different properties than others (although properties such as e.g. Current are good across the board).
Flat Hierarchies
In practice what sometimes happens is, the devices being controlled are in fact all practically identical and all devices provide the same set of properties and each property can be applied to each device. Such a situation is a flat browsing hierarchy, meaning that the list of devices supported by the server can be queried once and the list of properties can be queried once, giving all relevant browsing information concerning this device server.
Device Oriented Hierarchies
We had mentioned the case where perhaps a device server is providing an interface to similar hardware (e.g. PSCs) from different vendors. In such cases, any selected device (DOOCS location) might be expected to support its own set of properties. Thus in a browser, one needs to gather a new property list every time a new device is selected.
Such servers are referred to as device-oriented and have device-query precedence.
All DOOCS servers fall into this category, as they all tend to support (as the initial device) the server-host location. Many well-known TINE servers are likewise device-oriented (e.g. magnet servers, video servers, RF servers).
A browsing tool such as the Instant Client can easily discover whether a server falls into this category and automatically offer device-query precedence.
Property Oriented Hierarchies
Some servers provide services that tend to be more property oriented. In such cases, the primary point of contact, the focus, if you will, is the property. For instance, we know before hand that there is a property Pressure (or we browse our way there) and then learn what devices are supported for this property. The same server might have property MagnetCurrents with a completely different set of supported devices. The classic example for such a server is the TINE Central Archive server.
Other servers naturally partition themselves into different categories of properties, each of which likewise has a different set of supported devices. For instance a CDI Server has standard bus properties, but also TEMPLATE properties, Database Management properties, and extended properties.
Such servers are refered to as property-oriented and have property-query precedence.
For such cases, a browsing tool should be prepared to gather the set of supported devices whenever a new property is selected. To this regard, we note that device is in many cases a misnomer (as is the term location).
Frequently the items populating a device list can better be thought of simply as keywords.
A browsing tool such as the Instant Client can easily discover whether a server falls into this category and automatically offer property-query precedence.
- Note
- Note that the naming hierarchy remains as /context/server/device[property] as always. Also note that as DOOCS does not support property-query precedence, browsing tools offered in DOOCS do not (as of this writing) support property-query precedence and generally offer an abbreviated list of (often incorrect) devices when landing on a property-oriented server.
Registered Properties, Meta Properties, and Stock Properties
Registered Properties
So both DOOCS and TINE offer and refer to properties. As noted above, a property is a coverall term for an attribute, a method, or a command. In general, one way or another, a server registers its properties. Such properties are referred to as registered properties, to distinguish them from stock properties (see below) and meta properties (see below).
All registered properties have a handler. When a server intercepts a request from a client, it will ultimately dispatch the request to the provided handler. And this is generally where the server programmer comes into play. In general the handler will be provided with the input data set, if any, sent to the server as well as the nature of the requested output data set, if any. As to the requested output, DOOCS is more or less stateless and transactional and the client simply gets the results of the call (i.e. what the handler wants to send). A TINE Client can achieve something similar by requesting data type CF_DEFAULT - and providing enough buffer space to handle whatever comes back. However, TINE is not stateless (far from it), and the nature of the request always lands in a contract table. In any event the TINE API allows a contract's input and output data sets to be independent from one another and provides for an independent access parameter to indicate, among other things, a READ or WRITE. And a WRITE call from a client (and you can't say this often enough) has nothing to do with whether there are input data or not!
An attribute property, will typically provide both READ and WRITE access with input data type = output data type, i.e. your typical getter-setter.
- Note
- In TINE you can have atomic WRITE-READ transactions. In DOOCS one typically makes two independent calls, first the WRITE, then the READ.
A method property implies a more complex relationship between input and output data, where input data might be information needed to complete the call and not in anyway imply a WRITE command.
- Note
- In DOOCS or rather in jddd it is next to impossible to access non-attribute methods. DOOCS/jddd will assume that any input data type must be the same as the discovered output data type, and will only ever be able to send a single value as input.
We just used the word command. A command will be any property accepting WRITE access (and will be noted in the commands.log file). A command, however, does not mean that any input data need to be supplied! Nor does a command require output. For example, a property called INIT or START, etc. could be called with access = WRITE and that is all that a handler would need in order to complete the action and return a transaction status.
- Note
- In DOOCS, one generally needs to send something as input for such properties. In fact, jddd does not even provide for a simple command without input.
Meta Properties
All TINE properties naturally provide in internal handler for meta properties. meta properties, as the name implies, provide additional meta information about any particular registered property. For instance a property's maximum and minimum settings (its range) can be obtained by calling property.MAX and property.MIN. The available meta properties on offer are shown in the section on Meta Properties.
In TINE a call to a meta property might come back with no relevant data, if none are available. For instance if no maximum setting was registered for property P, then the caller of P.MAX will receive '0' as the returned value. If no local history is configured for property P then P.HIST will return the error status un_allocated. A call to the stock property (see below) METAPROPERTIES will in fact return a list of those registered properties with valid meta properties.
Although DOOCS will handle a meta property call internally, the meta properties in a DOOCS server are explicitly registered.
In TINE a meta property can be explicitly registered as well, which serves to override the embedded meta-property handler in TINE. Thus turning on the TINE thread in a DOOCS server will end up overriding the embedded meta-property handlers in the TINE layer.
Likewise, some TINE servers might want to override an embedded handler, as the embedded handler will often return static information. For example, a device-oriented servers might want to handle a call to P.MAX itself, as the output might depend upon which device was selected,
Stock Properties
All TINE Servers have a stock set of properties which can be called by any client. These are (coincidently) referred to as Stock Properties.
A good many stock properties are purely FEC specific (e.g. ACCESS_LOCK, SRVSTARTTIME, etc.), a servers's device name does not play a role, while others are server specific (e.g. DEVONLINE, DEVLOCATION), where the device name does play a role.
DOOCS Servers tend to provide a server location device (first one in the list), whose properties sometimes give similar information found in TINE stock properties.
Multi-Channel Arrays and Wildcards
Multi-Channel Arrays
TINE offers the systematic concept of Multi-Channel Arrays. That is, some properties, e.g. Pressure apply equally (same settings, same units, etc.) to all devices. It is thus sensible to offer a readout of such a property as an array of all devices. This is then the initial interpretation of what is meant by a multi-channel array (MCA) in TINE. This is a valid array, just as a spectrum array (i.e. a trace or waveform) is an array (e.g. an RF modulator pulse). It is likely an array of, say, floating point values just as a spectrum array might be, but here the elements in the array refer to device channels.
Wait! We're not finished.
With a properly configured MCA you can still acquire the data value of just a single element in the array! You simply specify the device you're interested in and ask for 1 element. You can also ask for a range of elements, e.g. "start at the device I've specified and give me the next 10 in the array), although that is seldem used.
Wait! We're still not finished.
A MCA property lends itself well to a form of contract coercion which decreases the client load on a server considerably! Namely, application panels are prone to ask for multiple (if not all) devices of an MCA property individually, e.g. all vacuum pressures, all magnet PSC currents.
If this is done in a publish-subscribe monitor mode, then the target server will inform the client (quietly) to obtain the entire MCA and pick out the specific element corresponding to the channel of interest. Thus if there are N pamel widgets acquire each of the N channels, the end result is that the server is just doing one thing, namely acquiring an array of all channels and sending it regularly to the client, which knows how to extract the channel information each widget wants.
There are also N advantages to archiving the entire MCA as an archive record, rather than each element individually. Although, here is must be said that if so archived, and the order and/or number of channels in the array changes regularly, then such archive records, should be marked as volatile, so that the archive server is capable of matching a device name to an array element at all times in the past.
DOOCS does not have this concept, but is nonetheless capable of supporting it via TINE. As a TINE server, the DOOCS property SVR.TINE_MCA can be used to specify which properties should be registered (in TINE) as MCA properties.
When a property is so registered, a browsing application (using TINE) will see in addition to the DOOCS devices addition group devices for each configured MCA property. e.g. a \dm device DEVGRP0
The properties acquired via query - remember a DOOCS server is always device-oriented - will be those MCA properties which support the given group device.
In addition to properties you may have expected, e.g. P, there are member properties, which give the list of devices - doocs locations - which compose the channels in the MCA.
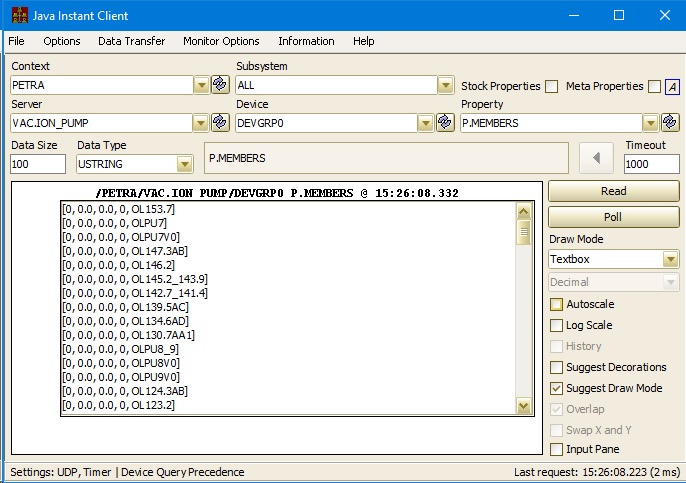
Now, what about status?
Suppose one (or more) channel(s) has some sort of error, but the contract coercion ends up making a single call to the server to get the entire MCA for the chosen property. That single call is for an array of, say, 100 floating point values and delivers a single status. How does the call behave? How should the call behave?
Several strategies might be in place. The simplest is: if any one channel has a problem (a hardware error or whatever) then the status for the entire array reflects that error. This approach is ... okay ... but takes erring on the side caution perhaps a bit too far.
Another strategy is to always return success, if at least one channel in the array is valid, but to flag any channel with an error with some clearly un-physical value (-1 is popular), so that the caller will know that such channels are suspect.
The best strategy is to register the MCA property so that it delivers a doublet (such as FLTINT) array giving an array of value-status pairs. And to overload the same property to provide a singlet (just FLOAT) array. The contract coercion will see to it that the larger array is the one providing the data at the client, and the client will see the proper status for each channel.
Wildcards
Now the typical way of acquiring an array of values in DOOCS - e.g. the same pressures in property P - is to make a wildcard call. In other words, instead of a specific device, you pass a * as the device and ask for, well ..., the property you want. Now you don't know what's going to come back, and you would like to know which value belongs to which device. And you would also maybe like to know the status of each device. So you will have to ask for a data type that can tell you all of these things. DOOCS generally requires a USTRING type. And you should ask for enough. You don't know how many will actually come back, but the call will be truncated to just the number which came back. Of course if you make this call in DOOCS, you will just get the result that the server wants to send you, which will be of the right type and length. But also here, you don't know what will come back until you look.
Here's an example:
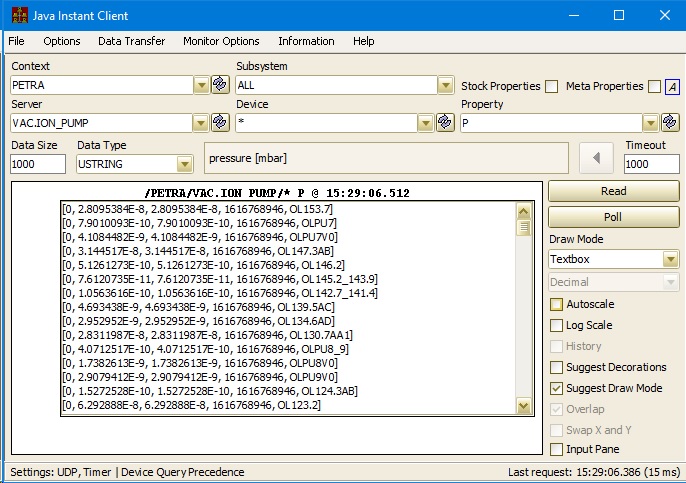
Also note the sleight of hand, in that you somehow knew that there's a property P, probably because you've browsed a few other devices and noticed that they have a property P. But * is not in any way, shape, or form a device - or location. And perhaps you've done this so often, that it seems logical, maybe even elegant. But you have just crossed over into a very property-oriented way of looking at the server.
Also note that by acquiring a USTRING (96 bytes) instead of a FLOAT (4 bytes) you've just increased the amount of data needed by a factor of 24.
Now, TINE servers also support wildcards - and even wildcard property calls -> the values of all properties for target device. And if a subset of values for e.g. device = WL* is desired, then that is perhaps a viable method to use. Other (better?) strategies include providing such filtering criteria as additional input or to get the entire multi-channel array and do the weeding out at the client.
This wildcard method for acquiring all values of some property is significantly clumsier than accessing the MCA itself, where possible.
Archiving Strategies
Local Histories
The primary DOOCS archive is its local history system (the DOOCS DAQ is another kettle of fish altogether).
TINE likewise supports local archiving in its local history systematics. Both TINE and DOOCS allow access to a property's local history through the meta property .HIST. That is, a property P will provide the history of P via the meta property P.HIST.
In addition, TINE will provide snapshot histories of the property P (i.e. the entire stored record - be it scalar, array, or structure - at a given time ) via the meta property P.HIST. DOOCS will also frequently provide additional history related meta properties such as ._HIST (with a leading underscore) providing annotations and ._HSTAT providing statistics (thumbnail statistics). These latter items are covered in the TINE stock properties HISTORY.CMT and HISTORY.CMTS (annotations) and the meta properties .RBMAX, .RBMIN, .RBSUMMARY (thumbnail statistics).
Both TINE and DOOCS keep local history files of the archivable records in a binary format, which basically means that the data are accessible only via a running server through the aforementioned meta properties, or perhaps via a local file scanning tool (to be implemented) which is able to read and decipher the contents of the stored binary files.
One significant difference in the writing of these files is that DOOCS maintains an always open file strategy, whereas TINE maintains an open-write-close strategy. An always open strategy perhaps saves a bit of time finding the file on the file system prior to each history data append. However, as the file i/o is often buffered, this does not amount to any serious extra CPU usage for the server.
The issue that the always open strategy presents relates to the fact that DOOCS server can only archive single value properties, and not e.g. a multi-channel array. Thus archiving e.g. 1000 vacuum pressures will all by itself produce 1000 open file descriptors (instead of archiving ALL values as a single MCA). As file descriptors fall into the same category as socket descriptors, there could be (and has been) interference, depending on initialization sequences, when an inordinate amount of DOOCS histories are active.
In any event, both in TINE and in DOOCS, local history data is typically only kept for a few months, although there are steps to preserve local history data.
Central Archive
The TINE central archiver, on the other hand, is designed to keep archived data essentially forever, and to make it available on-line at all times. There are a number of filtering strategies to keep the volumn of stored data to a minimum. The central archive is otherwise a perfectly normal TINE server (actual a pair of servers). This is in contrast to the DOOCS DAQ, which is not a DOOCS server and is designed to store all data (without any filtering of redundant data). However only the most recent two weeks of data are on-line at any given time.
In the TINE central archive, the data are stored on disk in the same binary format as in the case of the TINE local history (basically timestamp and other stamp information followed by the full record data). As the data in the central archive is to be stored forever and be always on-line, more care is taken (usually) with the filtering criteria along with tolerances, so that redundant information is not unnecessarily stored to disk. The local history data, on the other hand, which is perhaps available for only a month or two might be stored with more detail. The thinking would be: the fine detail is mostly relevant within the past few months (when searching for problems, etc. is more likely). Otherwise, the longer term general trends available in the central archive are fine. This is not to say that the central archive cannot be configured to also store all the data (it sometimes is). But one needs to keep an eye on available disk space!
central archive vs. local systematics
Thus there are very frequently two sources of archived data, one perhaps more detailed than the other. The TINE Archive Viewer takes the strategy of asking each source for the number of stored points over the time range of interest (an easy query in TINE), and then makes a decision as to which source to use for the current display based on 1) are there at least 1/4 th as many points as the client (the Archive Viewer) is willing to display (typically 2000 - Why display many thousands of points if you don't have the pixels to differentiate among them?) and 2) does the other source have more points.
The central archiver knows how to find and redirect alls to its source, the original server with the data, which may or may not have a local history of the same data. The source server can also find its partner on the central archiver, by virtue of the fact that all keyword properties at the central archiver have a property alias equivalent to server.property, which is something that the source server of course knows.
Data Retrieval Strategies
Wait, what? The Archive Viewer is only willing to display 2000 points?
No. It has a setting for the number of points to obtain for the given time range. The default is 2000, but the user can change it to whatever he likes. Once again, if the pixel resolution is such that it makes no sense to display e.g. 10000 points (because most of them are sitting on top of each other), then there's no real reason to to make the central archiver (or local history) scan for that many points and transfer them over the net.
Along these lines there is an automatic raster which will skip over intermediate points between the two end points of the selected time range. The call is also so designed to ensure that points of interest (e.g. spikes, etc.) will not be skipped over. This is true, if no raster is specified in the call. i.e. a raster of '1' would mean: "Don't skip anything".
The Archive Viewer does not specify a raster. But it does provide optical zooming. This means if the user zooms in on a smaller time region, the archive call(s) are repeated for the new time region. Thus zooming in on a region of interest is sure to get all the stored data points. So start off with a time range of several months and you'd get up to 2000 points covering the range, which would be able to show you the trend, along with any spikes. Zoom in, and you would get a new set of up to 2000 points, etc. etc.
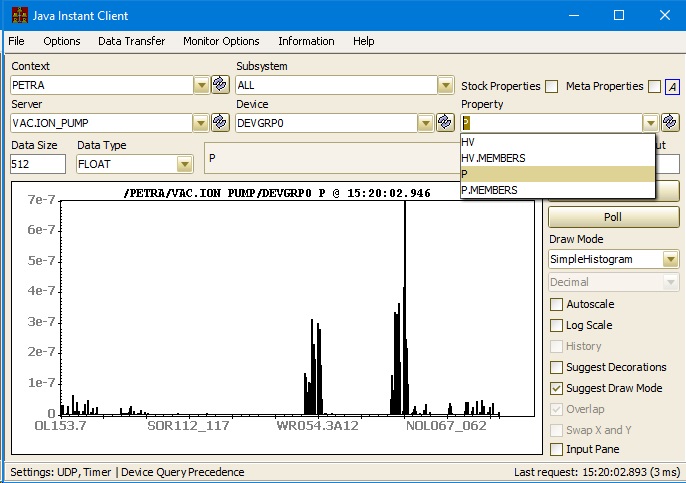
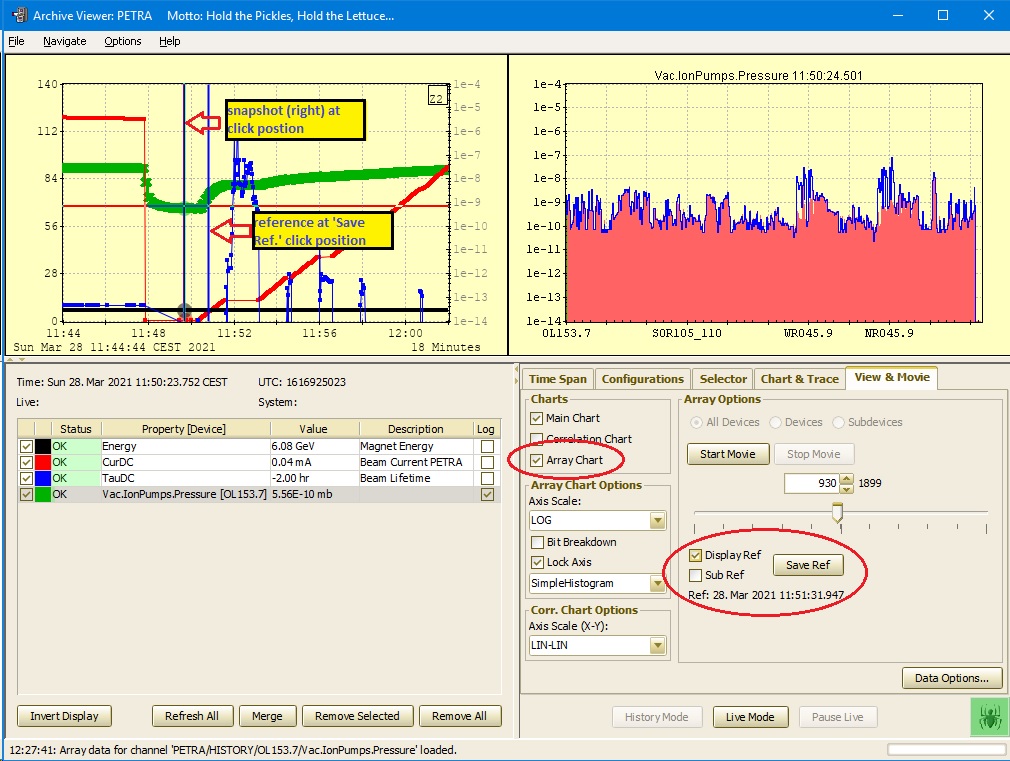
In the spirit of "A picture is worth a thousand words", here is an example of data sources and optical zooming. Have a look at the Va.IonPumps.Pressure for OL153.7 below:
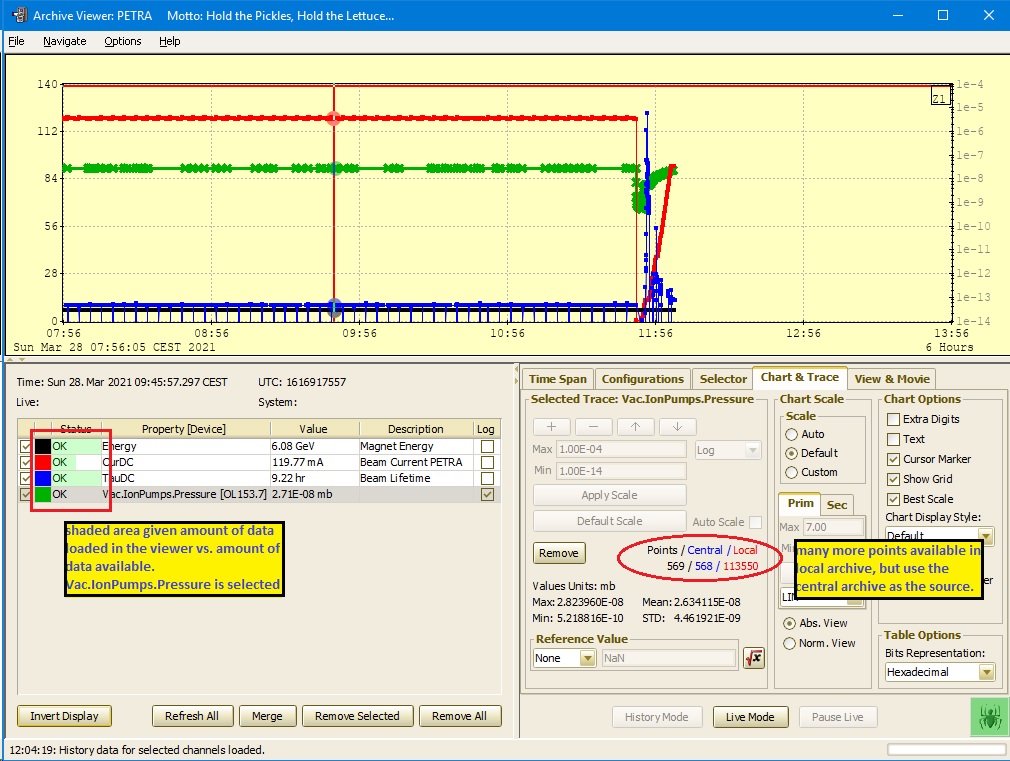
Now zoom in a bit more around the region of interest. Once the number of available points from the central archive drops below 500 (1/4 of 2000) the data source switches to the local history data, and there are still only a fraction (575 of 9208) of the available data points displayed in the viewer (so keep on zooming!).
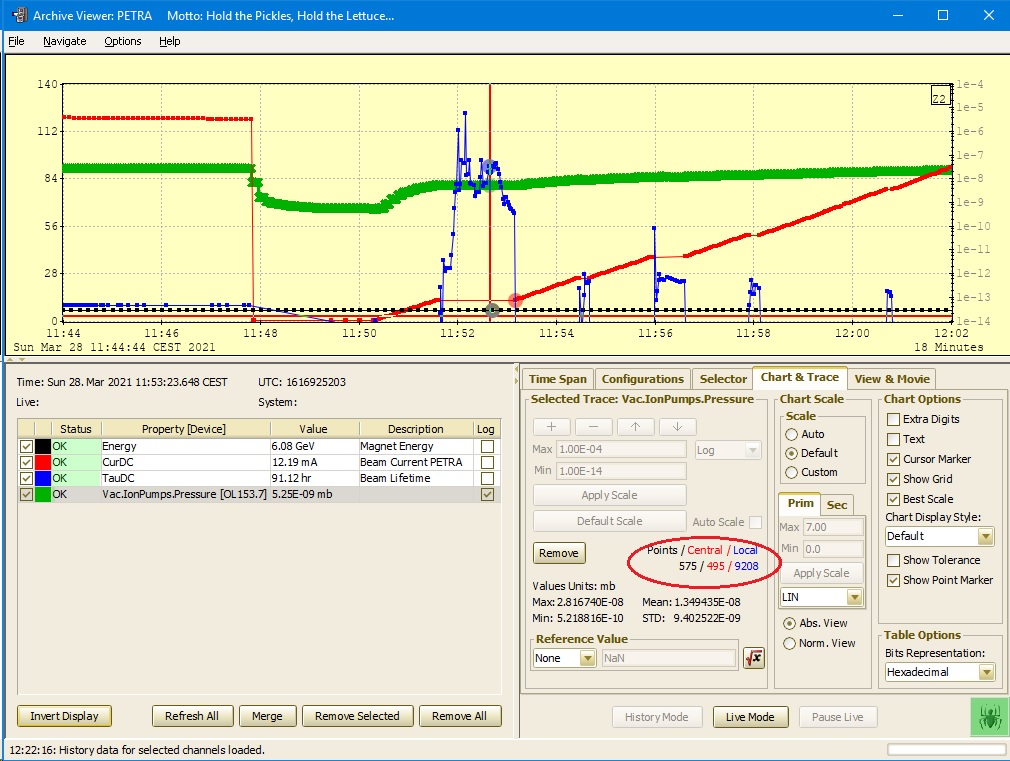
An added attraction of the store entire multi-channel array as the archive record is that the Archive Viewer can quite easily allow the user to view a snapshot of the entire array record at any particular time. Just click. (And check the Array Chart check box under View & Movie.
DOOCS history calls do not offer optical zooming. Instead the strategy there is to get all the points. This requires a strategy of make-the-call-from-time1-to-time2 for some maximum number of points, see if and at what time time3-the-returned-data-stopped, then use-time3-as-time1-and-repeat-the-call until you have reached time2. This is of course the stategy you would need in TINE in order to get all the points in an interval - with the sampling raster = '1'.
What can be Archived?
In TINE any supported data type, including user-defined structures can be archived, both centrally and locally.
Now in the Archive Viewer (as well as most known archive display tools), the immediate and most common display of an archived parameter is the trend of the parameter over some selected time range. And this is by and large what you want to see for attribute style parameters, or elements of a multi-channel array.
To this end this is all a DOOCS local history can do. More complex entities, e.g. a modulator pulse, accessed as a spectrum type array (maybe even one of those DOOCS SPECTRUM typs), cannot be archived in DOOCS. Instead they can appear in the DOOCS DAQ system (which is something else), if need be.
TINE has no difficulties archiving such items, and can archive video images and even structures.
The issue here is what to display in trend view. Generally, for an array, the user will select an array element (usually the first) to use in the trend chart. Then the user activates the Array Chart and selects a time of interest by clicking in the Trend Chart. If a Video Image is selected, then the frame number is typically shown in the trend chart. For structures or complex data types, the Archive Viewer user needs to specify the field in the data type that should by trended.
Scheduling Data Delivery
Publish/Subscribe
DOOCS has traditionally made use of synchronous SunRPC calls as the basis for communications, where a DOOCS server is an RPC server and a DOOCS client is an RPC client. Thus only synchronous, transactional polling of a DOOCS address is possible in this traditional mode. This of course means that any particular call is stateless, which is by itself a good thing, in that it simplifies life and logic. i.e. Ask a server for property P and it will send you the result and then forget about you. It will also forget that it just did this, if another client is waiting in the wings with the same question.
So there are no connection tables, contract tables, client tables, etc. do deal with.
Life is easy! Easy to get the code right (well okay, there is still some thread safety to worry about). Fewer timeout messages, as the server does not have a sense of what it should be doing for its clients, and a client would only note a timeout for a particular call (in a particular thread) when a client-side timer has its chance to poll that particular call.
This is all fine, but tends to lead to load problems and a DOOCS-oriented Einstellung (google this in a psychological context) to solve these problems.
TINE of course provides transactional synchronous communication as well. But it also provides publish/subscribe and producer/consumer communication. In particular publish/subscribe is the major work horse as to data flow from servers to clients.
So you can forget about stateless. A TINE Server must keep track of its clients and what they want, when. And clients can request updates on TIMER (e.g. every 1000 msecs, please) or on DATACHANGE (only when the data have changed) or on EVENT (only when the server decides to send).
Tantamount to being able to do any of this is the server-side scheduler. When the scheduler is accessed, (and it is regularly accessed!) it checks its contract tables in order to see if it is time to call somebody's property handler. If so, it does this and looks at the results of the call and makes a decision to send data to one or more of its clients or not.
Scheduling Delivery
Now you are ready to understand the concept of Scheduling.
The server programmer can call the scheduler at judicious times when deemed necessary. i.e. There is an API call to schedule a property (you can also schedule the property for a specific device), which does in fact call the scheduler, which in turn checks it there are any contracts in its tables involving the scheduled property, and if so, then the handler will be called and the data will be delivered now.
This scheduled delivery is, by the way, independent of a client's requested delivery mode (TIMER, DATACHANGE and EVENT all would receive the update now).
Generally, the server programmer must know the best time and place to do this.
Is it just after the hardware has been read? i.e. Schedule on hardware trigger? Or is it only if the server notices a data value of interest has dramatically changed? Schedule on an event tolerance?
There is a gentleman's agreement, that if a server is scheduling on hardware trigger then the property being scheduled should have the meta attachment .SCHED in its property name. e.g. BunchCurrent.SCHED if a client monitoring this property is to expect to receive data at the hardware trigger rate (regardless of the polling interval specified). The same gentleman's agreement is that an additional property without the .SCHED maps to the same property handler, so that clients who do not want updates at e.g. 10 Hz but rather at the monitor interval given can get what they want.
How to schedule data in DOOCS
You can also schedule DOOCS properties! You would need to specify those DOOCS properties which should be scheduled via the server location property SVR.TINE_PSCHED.
But you wouldn't be finished. Because, only you can know when and at what spot in the code to call the scheduler. To this end, you (the doocs server programmer) should place the call
set_scheduled_props();
at the precise spot where any listening clients should be notified of a change in data values. If this is a hardware trigger schedule, then listening clients will get updates at the trigger rate, otherwise you might need to do some only-do-this-when checking before calling set_scheduled_props().
Of course this only works via TINE protocol, as the DOOCS synchronous polling strategy does not support this.
Log files
TINE log files
A TINE server maintains (by default) several log files. The most noteable is perhaps fec.log, where most initialization activity and results are output along with import state changes during the lifetime of the server. These might include time synchronization notifications, commands and security violations along with anything else you might log via the feclog() API call in the server code.
If system logging is turned off via SetSystemLogging(FALSE) then a server will still maintain a virtual log file main memory for the lifetime of the server process. In general you will want a hard log file, particularly if things go awry during startup. Some platforms, such as VxWorks do not normally have a disk, so a virtual fec.log is the only option.
A DOOCS server with the TINE thread will by default not have a fec.log. This will need to be turned on (and we strongly encourage this!) via setting SVR.TINE_LOG=1.
fec.log will log up to a fixed number of lines (i.e. effective 80-character lines). By default this is 1000, but can be augmented via API or environment. Once this limit has been reached there is one rotation where fec.log is moved to fec.bak.
The log files are of course accessible on the host machine, found in the directory given by FEC_LOG or FEC_HOME (if FEC_LOG is not set) or in the server's working directory, if neither is set.
The log files can be accessed via the stock property LOGFILE (for fec.log and fec.bak) or SRVLOGFILE where the device name (here it really is a misnomer) address parameter specifies the name of the log file.
For instance, the Remote Control Panel displays log files thusly:
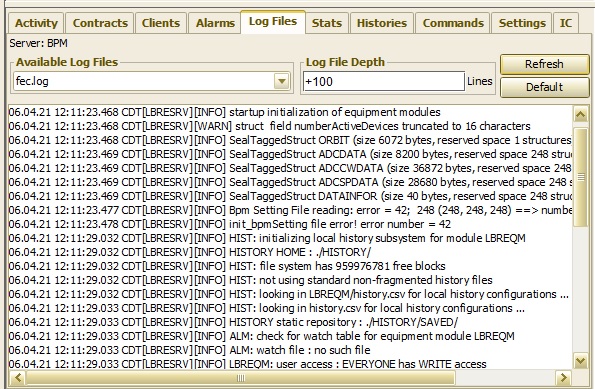
shows the initial few lines of fec log of the PETRA BPM server following a start.
A TINE server likewise maintains a separate error.log file, where the warnings and errors from fec.log are logged again separately - making it easier to focus on the problems.
And a TINE server also maintains a commands.log file, showing external commands (with input) in a separate file. This is generally more informative than the COMMAND notification in fec.log. The entry in commands.log however only shows that the server's property handler will be called. It does not show the results of the call.
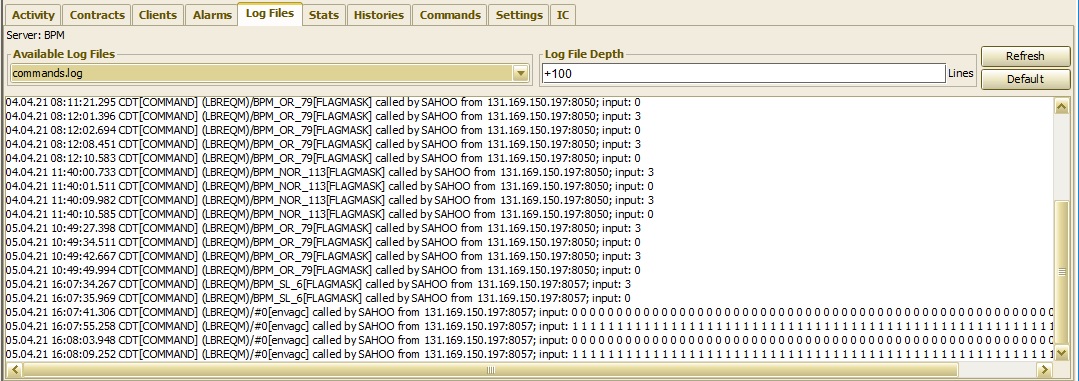
shows the last several commands send to the PETRA BPM server.
The server programmer can also maintain his own log files by making use of he API call srvlog().
DOOCS log files
In DOOCS you essentially write what you want to have in a log file to the standard out (stdout) via e.g. printf() or cout <<. DOOCS servers are generally started in the background where the standard output has been piped into a log file.
Ports of Call
Any server (TINE or DOOCS) will have one or more listening sockets with a specific known port address, to receive incoming requests from clients. For a DOOCS server this will be given by the SunRPC Number. For a TINE server there are several possible listening sockets (i.e. ports). Among others: one for UDP requests, one for TCP requests, one for remote debugging. A TINE server will have system-wide known base port addresses and apply a server specific port offset to each of these base ports.
By default a DOOCS server with SVR.TINERUN=1 will use the SunRPC Number as the TINE port offset.
This will generally work just fine. However on rare occasions a port conflict might ensue (e.g. one of the listening ports will try to bind to a port already in use by other running hardware or software. In such cases the TINE layer will make a note in the server's log file, but be otherwise unable to serve. Should such a situation arise, the TINE port offset can be fixed by setting the DOOCS configuration parameter SVR.TINE_PORT. By default this is set to 0, which is a signal to use the SunRPC number. You can set this to any positive number (which should be unique to the host workstation and chosen to avoid the port conflict. Another alternative is to set the SVR.TINE_PORT to -1, which is a signal to obtain a valid port offset from the local server manifest. However note that this last option would only avoid conflicts with other TINE server on the same host and would not be able to discover a conflict with other running software.
Split Servers and TINE Group Servers
For whatever reasons, a DOOCS server (i.e. a DOOCS DEVICE in doocs terminology) is often not a single server on a single host process but a group of server processes on multiple hosts. Thus in a browser, you might land on a server called DEVICE_SERVER with multiple locations, LOCATION1, LOCATION2, LOCATION3, and so on, where LOCATION1 and LOCATION2 might be serviced by a doocs server process on HOST1, but LOCATION3 is serviced by a doocs server process running on HOST2, etc.
Such a split (DOOCS) device should be mapped to a TINE group server when registered in the TINE world.
One problem is that the first thing someone learns about configuring a DOOCS server to be accessible to TINE is that "It's EASY! You just have to turn on the tine thread!" (SVR.TINERUN=1).
Alas, that is only true, if the server in question is NOT a split doocs device server! Because if it is, then you have probably just shot yourself in the foot (at least initially). This is because you have likely not paid any attention to the GROUP METRIC, which should be specified along with that SVR.TINERUN=1. You provide this via another DOOCS configuration variable: SVR.TINE_GROUP.
For each member of the GROUP SERVER you should provide a different group metric. i.e. SVR.TINE_GROUP=1 for the group member whose devices (doocs locations) should appear at the beginning of the device browsing list, SVR.TINE_GROUP=2 for the group member whose devices should appear next, etc.
If you do this correctly and PRIOR to turning on that famous thread, then everything will be fine.
If you have already set SVR.TINERUN=1 everywhere, either on-the-fly or prior to a server start, then you will have encountered the situation where the first server to register itself with the TINE ENS (remember that TINE is largely plug-and-play) will have anchored the name DEVICE_SERVER for itself and any other member trying to do the same (AND THEY ALL WILL TRY!) will be rejected by the ENS, because the server name DEVICE_SERVER in the context (doocs facility) given has already been assigned and the server is running under that name.
Providing a GROUP METRIC via SVR.TINE_GROUP=1, etc. will attempt to register a server called DEVICE_SERVER.1, etc. and assign it with metric '1' to a server group DEVICE_SERVER.
However a problem will arise if you have already turned on the thread without the group information.
In that case the server name DEVICE_SERVER has already been assigned and that server is running. The new server DEVICE_SERVER.1 will register itself, but the GROUP server DEVICE_SERVER will be rejected, as that name is in use and that server is running (It's now an alias for DEVICE_SERVER.1 !).
Thus, trying to post-correct your earlier blunder by adding the SVR.TINE_GROUP information after the fact will indeed register all of the member servers (DEVICE_SERVER.1, DEVICE_SERVER.2, DEVICE_SERVER.3, etc.). BUT there will NOT be a proper group server (analogous to the split (doocs) device) visible. Instead you would be able to see and browse to a server called DEVICE_SERVER, but that would merely be an alias to e.g. DEVICE_SERVER.1, i.e. the first member of the device group.
There are two ways to rectify this situation.
Method 1: Use the TINE ENS Administrator to remove the server DEVICE_SERVER in the appropriate context.
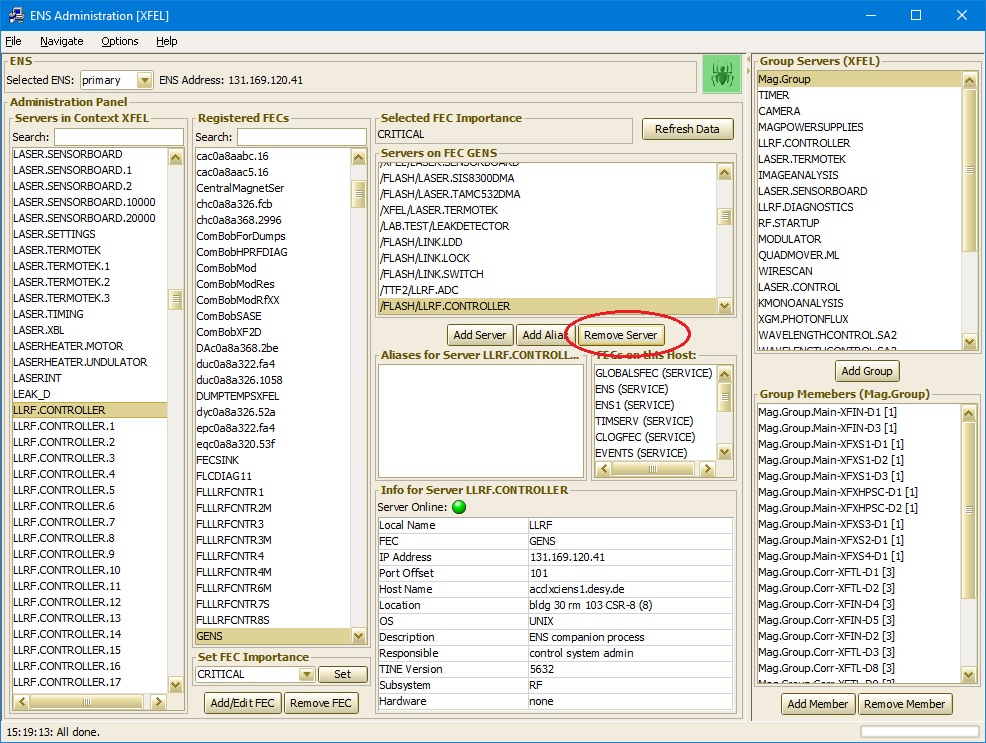
Then restart one of the member servers. The ensuing plug into the ENS should then be then able to register the proper GROUP server as well.
Method 2: Make use of the enabletine command line tool (as user doocsadm or some user with the necessary rights to all the server members.
Below is an example :
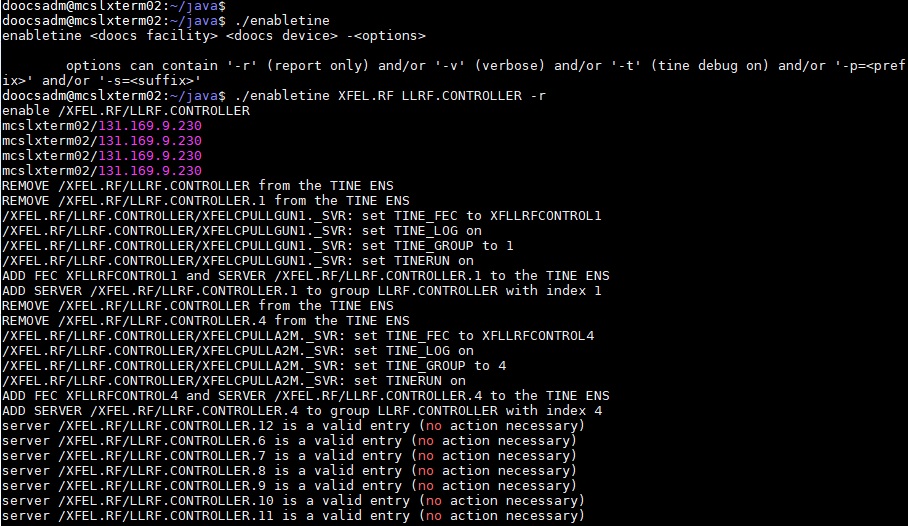
The advantage of using enabletine is that this tool queries the doocs ENS database for the official group metrics (as seen by the doocs ENS) and makes use of them. The tool can also post-correct all improperly configured servers and do this on-the-fly.
