Introduction
Archiving is an important aspect of any control system and is all too frequently ignored during the initial commissioning frenzy, where being able to control the equipment is the primary concern. However, when things go wrong or are otherwise not behaving properly the archive system remains the best diagnostic tool for figuring out why.
TINE offers three different systematic ways for archiving data:
- Event-driven archiving
- Central archiving with adjustable state and tolerance filtering
- Local archiving tolerance filtering only
Event-Driven Archiving
Event-driven archiving, sometimes referred to as "post-mortem" archiving is discussed where we discuss the TINE Post-Mortem/Event Archive System
Central Archiving
Central archiving consists of acquiring the specified data, passing it through the relevant filters and writing it to disk if warranted. This is managed by a pair of TINE servers running on the same machine or otherwise sharing the same file system. The first server (or server process, if you will) is designated as the "archive server" and is responsible for collecting the data and committing it to disk. At the same time, the server can act as a gateway for the current values of all properties and channels it is collecting, and fills the role of a "netmex" server ("netmex" stands for NETwork Machine-Experiment eXchange: please see the discussion on the netmex system).
The second server is designated as the "archive
reader" and is responsible for handling all requests for archive data. So it is clear that both server processes need to share the same file system. It was deemed prudent to maintain two different server processes in order to have a clean separation between the data taking and the archive data request handling. For one thing, archive requests from the "archive reader" for large amounts data may require a few seconds to scan and locate the data required and this amount of time should in no way hinder the data collecting functionality of the "archive server". Theoretically, a single server could utilize two different threads for these two activities. However the only data these two processes need to share is on the disk, hence it is a much cleaner solution to keep two different servers, where either server can be restarted without influencing the other.
The Archived data can be retrieved with various tools, from a command line query to archive browsers such as the TINE Archive Viewer. Below is screen shot of the TINE Archive Viewer.

The stored data are maintained in a local database in binary format, one file per dataset per month. The configuration portion of the database consists of simple ascii comma separated value (csv) files, which contain the instructions for the archive server as to how to collect the data. These "instructions" amount to nothing more than giving the TINE Link parameters to use for the individual servers. Thus the archive server will maintain a long list of data links to servers in the control system. Each data link will have a distinct fixed record length and an archive index assigned to it. As the index and record length are known, data lookups in the binary database are very fast, even when large amounts of data covering a wide range in time are requested. The stored-data database is contained within a parent directory named 'DATA'. The directory hierarchy then proceeds with year (numerically as 'YYYY') and then month (numerically as 'MM').
Within each month folder, each record will have one file with the name 'arYYMM01.<record number in hex>', where the 'record number' is assigned in the configuration database. This naming convention satisfies all platforms on which TINE is supported, including MSDOS. Thus if record 17 contains the orbit data, there will be a file "../DATA/2003/12/ar031201.11" for the month of December in the year 2003. The parent directory 'DATA' is typically located parallel to the directory containing the archive server and the directory containing the archive reader.
Records
Although the data link instructions can use the full palette of possibilities as to how to acquire data, it is most efficient to obtain entire spectrum objects or multi-channel arrays as opposed to individual channels. That is, it is much better to get the entire orbit as one record (that is, two records: properties "ORBIT.X" and "ORBIT.Y") instead of 100 individual records, one for each BPM. The same holds true for say vacuum pressure, beam loss monitor spectra, bunch currents, etc. The lookups for individual monitors from an orbit are no slower if stored this way, but are much, much faster if a snapshot of the orbit at a given time is to be retrieved. If the size of the spectrum changes (due to the addition of new monitors, for instance) there are a couple of strategies which could be followed to ensure data integrity.
Two-Dimensional Lookups
As noted above the TINE archive reader offers two different ways to pull the data out for data stored as array spectra. In such cases, the archive data are of course two dimensional: a one dimensional array stored over time. So you can select an element of the array (a particular device or monitor) and ask for its history over a time span. Or you can choose a particular time and ask for the spectrum (or a portion of the spectrum) at that time.
For instance in the image below, the vacuum pressure from a particular pump (B 2/3 Q2/GP463) was selected in the parameter panel and by checking the 'Plot Array' check box a secondary display appears which shows the full spectrum (all channels) of the vacuum pumps at the time selected on the primary display.

Data Formats
The archive server and archive reader will do format conversion where possible.
Typically, one asks for an archived property or a particular device from a property array over a time range. The time range is specified by passing the start time and stop time as UTC long values (or double values) to the archive server as input data.
So the caller typically sends two values to the archive reader. If only one long is passed, this value is taken as the start time and the current time is used as the stop time. If no values are sent to the server, then the start time is likewise assumed to be the current time, which will result in returning only the most recently archived value. For time-range calls, the caller will in general request a doublet format for the returned data; e.g. CF_FLTINT, CF_NAME16I, etc. or more likely CF_DBLDBL. The data will then be returned as pair-wise data
- timestamp doublets. If an array spectrum at a particular time is requested, then the start time and stop time are used to specify the range in which to start looking for the closest match, and a simple format type (e.g. CF_FLOAT, CF_NAME16, etc.) should be used. The entire spectrum will be returned at the first timestamp encountered which falls within the time range given. The data timestamp of the call will then be set to the data timestamp read. Other request format types are also supported. A special histry retrieval format (CF_HISTORY) is also available (although this should not be used by the layman), which can 'carry' any other TINE format plus the time and data stamp information.
In most cases, a caller will make use of the 'ready' API calls available for accessing archived data. In java, these are methods of the THistory class. In C, these include for example GetArchivedDataAsFloat(), GetArchivedDataAsSnapshot(), etc.
Number of Data Records Archived
The caller can at any time ask the archive reader how many data records were in fact stored between a given time-range. The way to do this is to specify the time range as noted above, but to request only 1 value (of any double type format) in return. The integer part of the returned data will contain how many data points have been stored within the time-range specified. This is useful when the time-range given spans many days, weeks, or even months. Note that, the archive reader will check the size of the data buffer requested by the client and attempt to fill it meaningfully by skipping over intermediate records according to an appropriate raster. This feature can be overridden by sending an array of four long values to the archive reader. In addition to the start time and stop time as the first two long values, a '0' should be sent as the third element (index = 0), and a '1' as the fourth element (raster sample = 1). The archive reader will then not skip over any read data points, but instead stop reading when the caller's buffer is full. The client would then have to check the time stamp of the most recent data point returned and re-issue the call starting then.
Points of Interest
The central archive server (and the local history subsystem) will also maintain so called 'points of interest' whereby 'interesting' data is effectively 'marked' so that any archive request covering a time range containing these marked data will not 'skip over' them no matter what the defacto raster is. Thus a call spanning an entire day or week will nonetheless show those 'spikes' and 'dips' that occurred even if a good many data points were skipped over in filling out the request. Data points are marked as 'interesting' if change in the current data value and the last read value is greater than 10 percent of the registered data value range or if the change is greater than 10 times the registered tolerance. Note: both of these values (10 percent, 10 times) are adjustable (see SetPointsOfInterestRangeFactor(), SetPointsOfInterestToleranceFactor(). On the other hand, if the data range or tolerances are set so poorly that 'all' points appear interesting, then effectively 'no' point is more interesting than any other and the checks for points of interest is bypassed.
More Input Options
A caller can also request all data from within a time range and within a value range. To do this, one sends the archive reader a data object consisting of a CF_WINDOW object. This is nominally equivalent to CF_INTINTFLTFLT (integer-integer-float-float). The first two integer values give as before the start time and stop time of the requested time range. The two float values give the lower and upper limits of the data range.
Record Sub-Structure
Frequently the data link parameters (i.e. device name, property, size and format) used to obtain the data are the same as those used to re-export the data (as in netmex) or to retrieve the data from the archive. However this need not be the case. The TINE archive system is flexible enough to allow a data set to be collected as a single entity (for example, property "BLOB" as an array of 100 float values) and re-exported and archived with a more meaningful sub-structure, although the total record length must of course be the same.
Device Names
A central archive server is a classic example where unrelated properties are exported, each associated with its own device list. For instance, the device list associated with "VacuumPressure" will have nothing to do with that associated with "CollimatorPosition", although both are available from the archive server and archive reader. By using the TINE ".NAM" meta-properties it is a simple matter to solve this problem. Hence, in the above example, there will also be properties "VacuumPressure.NAM" and "CollimatorPosition.NAM". Offering device names is easiest way of associating array elements with a name, the alternative being the use of device numbers. In this way many of the archived properties become multi-channel arrays, where each element of the stored 'keyword' property refers to a specific 'channel', whose name is given via the associated ".NAM" meta-property.
Non-multi-channel properties (either scalar values or wave-form like spectra arrays) will not offer any specific device name. Hence the exported archive 'keyword' property should best be chosen to describe what the keyword refers to if the 'source' device name is relevant.
Sub-Systems
The archive reader also responds to queries as to how many and what kind of "sub-systems" are maintained. It can then return lists of archive records belonging to a particular sub-system.
Archive Filtering
Of course most people want all the data stored all the time at 1 Hz or more often.
Under most circumstances this is either not possible or not practical. Of course, if you have the storage capacity there is nothing in the TINE central archive system that would prevent you from doing this. However there are a number of filtering criteria which can be set to reduce the amount of data committed to disk to much more manageable sizes, making this a viable system even when run on a standard PC with a 100 GByte disk running linux. The first filter is the timestamp.
The timestamp must change to a more recent value than the last archived data before a new data record is written to disk. The next filter is the data itself. There is a configurable "archive heartbeat" (typically 15 minutes) which guarantees a data record committed to disk at least as often as this (provided the timestamp is changing!). However, if within this period the data do not change within a configurable tolerance, they will not be written to disk. The tolerance can either be absolute or relative. The next level of filtering deals with the machine states. You can specify that data are to be stored only if, or more often if there is BEAM or LUMI or if the machine is RUNNING or according to particle type, etc. We will see how to specify these filters below.
The archive server itself has several 'built-in' filtering criteria. These include the stock filters
- "NEVER" Never archive the value to disk. Only provide a 'netmex' data pump for the value.
- "ONCE" Archive the value only 'once' at startup (or following recovery from a time out). This is exclusively used for acquiring the 'device' names associated with a multi-channel array.
- "ALWAYS" Always archive the value to disk no matter what external filters are applied. The value will be archived no less frequently than the default archive rate (once per minute). This option might be used in conjuction with "FAST" or "SLOW" to further specify archiving frequency.
- "FAST" The value can be committed to disk at the configured update rate if the other filtering criteria are satisfied. The combination "ALWAYS+FAST" with an update rate of 1 Hz might write data to the disk once per second if the tolerance conditions and other filtering criteria are satisfied.
- "SLOW" The value should no be committed to disk more often than the default archive rate of once per minute.
- "FIXTIME" The timestamp of the incoming data should be ignored and overwritten with that of the central archiver.
- "HRT" Use "High Resultion Timestamps" and archive all other associated data stamps with the data (i.e. the system stamp and the user stamp). Under normal conditions of 'minimal storage', the archived timestamp is a UTC long (4 bytes) which will only contain the resolution of seconds. This is generally okay, if data are not archived any more often that at 1 Hz. If the disk capacity is large, and higher archive rates are desired, then this is obviously no good. In this case the "HRT" option should be set. The timestamp will be stored as a TINE timestamp (UTC double containing milliseconds), and the system and user data stamps (another 2 4-byte integers) will be stored along with it. This will cost more disk space per record.
- "STATUS" Instructs the central archive server to store the status of the data acquisition along with the call. As this is in general '0' if the data are being successfully acquired and if not '0' there is most often 'no data', supplying this option is often a waste of disk space.
- "VOLATILE" Instructs the central archive (i.e. archive retrieval) server that the parameters in question refer to a multi-channel array whose channel names are 'volatile' with respect to time. That is, the channel names might have been different (or had a different order) at any time earlier than the current time. Such elements require a bit more checking and scanning at the archive retrieval server. Thus, multi-channel arrays whose channels are known to be static (or static throughout a long time domain) should best not use this flag.
- "NOPOI" Instructs the central archiver not to keep 'points-of-interest' information for the record in question. If it is known a priori that a record will nearly always signal data points as interesting (because the tolerances need to be keep small, etc.), then it might be advisable to set this flag, so as to avoid archive retrieval confusion in the archive readers (too many 'interesting' points might fill up the archive retrieval buffer too soon, acquiring no data points near the end of the requested time range).
Other filtering criteria can be added depending on the nature of the machine running. The central archiver will look for (and read if present) a file called 'filters.csv' in its working area. An example is shown below.
Here one can define a filter called "BEAM" for instance and designate which keyword (which must be a parameter in the archive database) defines the validity of the filter. Along with the keyword, the format type and a validity range must be supplied. If the current value falls with the validity range, the criterion is deemed valid. If the filter criterion is a test string of some sort, then the validity range should include a matching (up to any optional wildcard characters) text string. In the above example for instance, the filter "SASE" is such a case. Information provided in the DESCRIPTION column will be used by the archive database manager as 'tool tip' text.
In general, you should not have to worry about editing or maintaining this file yourself, as the the archive database manager (see below) is quite capable of handling these tasks for you.
Database Manager
As noted earlier the data configuration database consists of ascii text .csv files.
If you know what you are doing you can edit these files by hand with any text editor or spreadsheet. However to facilitate matters there is also a TINE Central archive database manager. The database manager has full connectivity to the control system, thereby allowing queries to individual servers so as to discover available link parameters. It also offers input for all relevant fields in the database and insures that the collection parameter specification is not in conflict with the sub-system information for instance. BY default, it operates in an interactive mode accessing information from the archive servers directly. Finally, changes made to the database configuration can be uploaded directly to the archive servers. For this reason, the archive server itself should maybe be protected via an users access list to allow only 'official' archive system adminstrators access.
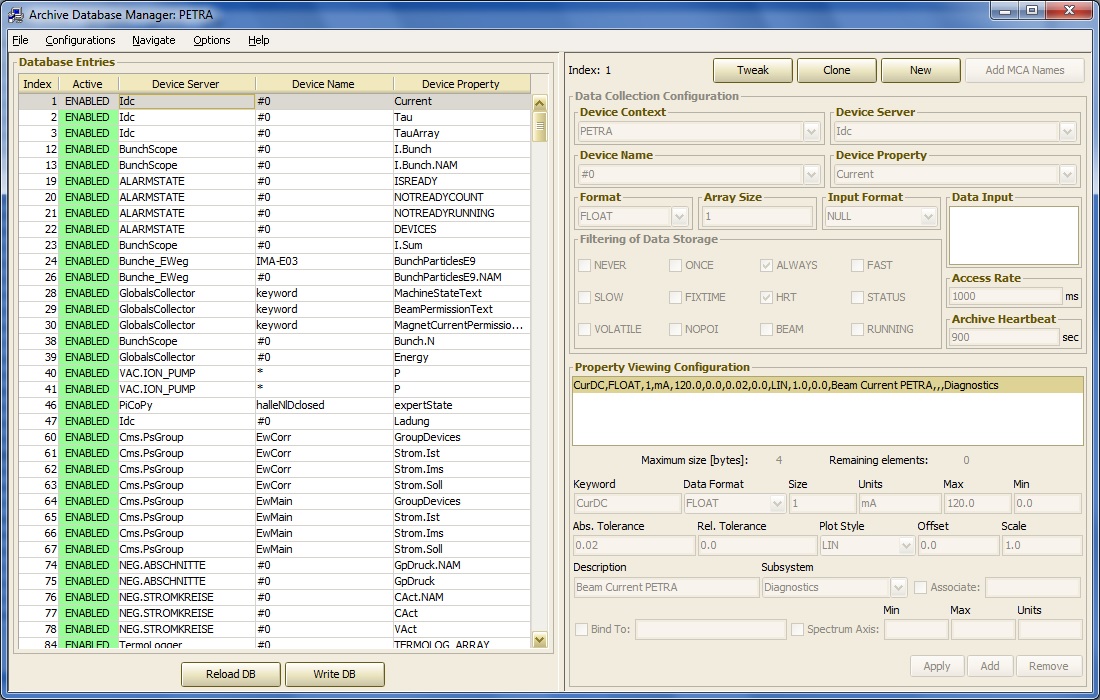
In the above example, the source item is the property "Current" from server "/PETRA/Idc". This is a simple scalar delivering single 'float' value. This item is then stored as an archive record named 'CurDC' at the central archive server.
Now consider:
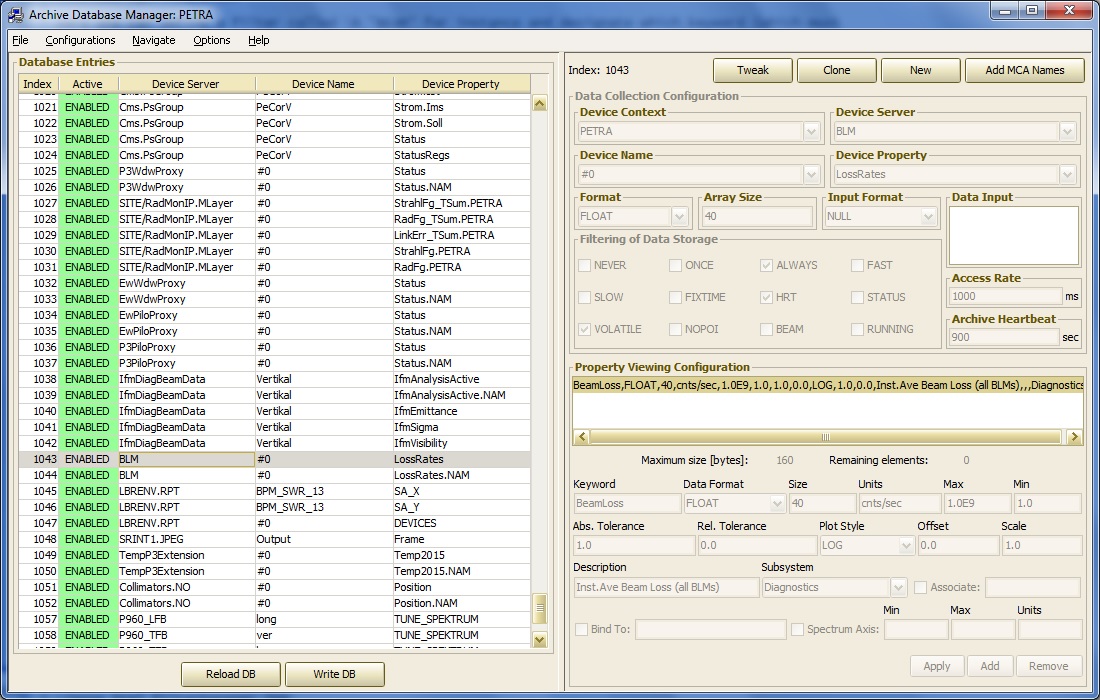
In the above example, the source item is the property "LossRates" from server "/PETRA/BLM". This is a multi-channel array at the target server, delivering 40 'float' values. This item is maintained at the central archiver as is configured to be stored as an archive record under the name of simply: "BeamLoss", also an array of 40 'float' values.
The database manager in fact ensures that the number of elements obtained from the target must be the same as the total number of elements which are stored in the archive record. The archive database manager will also query the target server as to units and maximum/minimum settings, etc. and offer them in the record display. This information can be edited (or supplied, if missing) via the database manager. In the above entry the 'Device Name' used to make the acquisition has been intentially edited to "#0" (i.e. device number 0), rather than the registered device name of device 0. The difference is in general irrelevant at the server but allows the data acquisition to be independent of the name of the initial device, which might change if new hardware is added to the target device server. The very next entry in the database is a data acquition of the property 'LossRates.NAM' (as an array of 40 NAME64 elements, filter = ONCE).
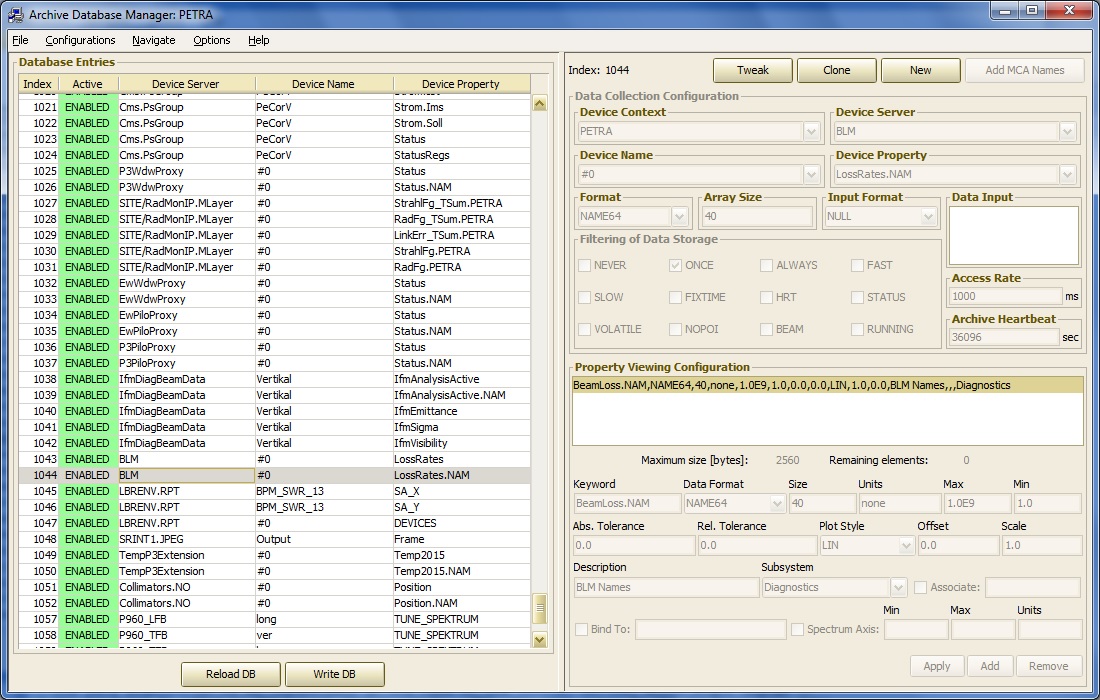
The stored record for this entry will provide the element names for the monitors providing the data for "BeamLoss" and should therefor be configured to have the name "BeamLoss.NAM" so as to effectively 'declare' the keyword property "BeamLoss" to be a multi-channel array.
For more information concerning the archive database manager please have a look at this demo
In addition, changes or additions to the filter criteria or to the viewer configuration can be made with the same database manager. Opening up the options menu, one sees:
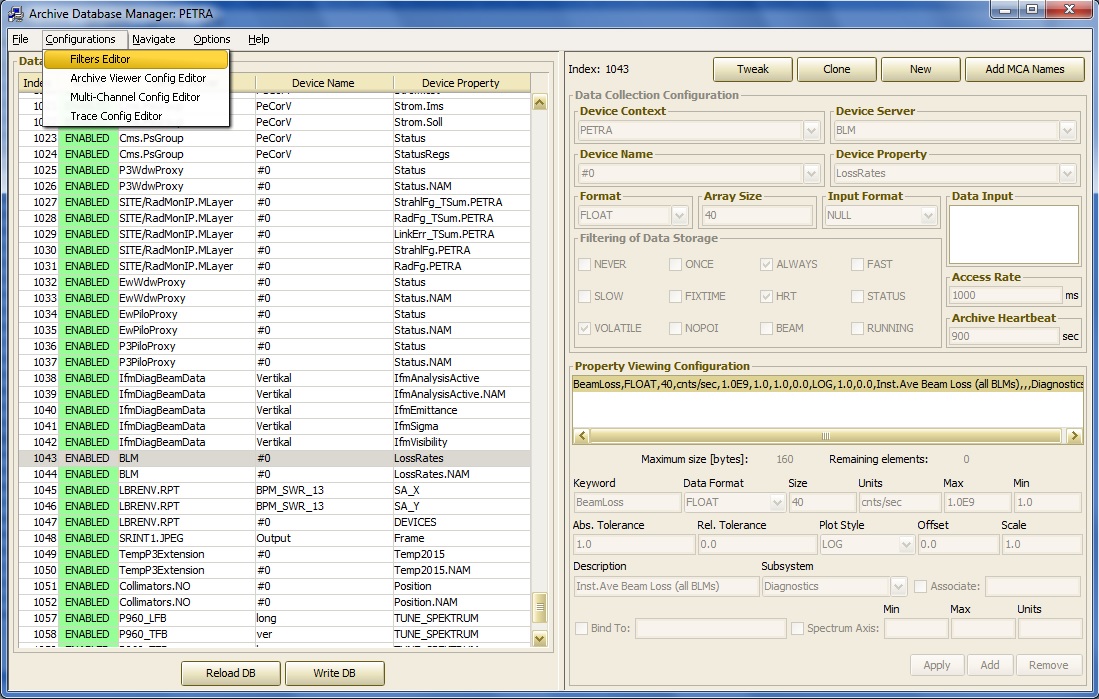
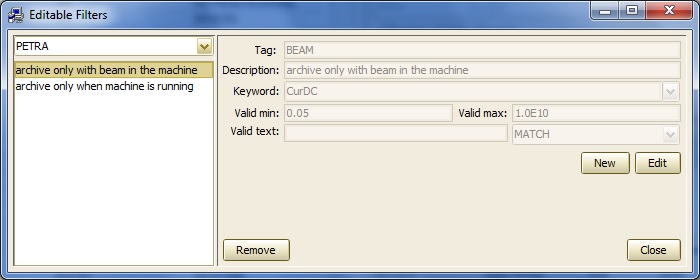
To examine the 'editable' filter options, choose the Filter Table Configuration and make any changes or additions using the popup window:
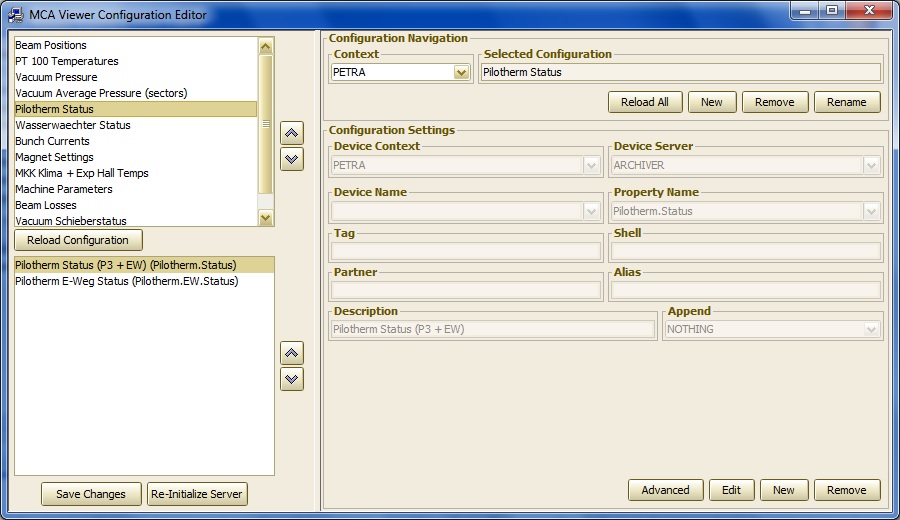
Viewer configurations can be edited or appended to for the Archive Viewer, Multi-Channel Array viewer, or Scope Trace Viewer by choosing any of these from the options menu. For instance:
Local Archiving
Local archiving takes place at the server, where the server can be configured to maintain an archive of specified properties both on a short-term basis (in main memory) or on a long-term basis (on disk). All TINE servers contain a local history server (LHS), but by default no histories are maintained. If a startup configuration file 'history.csv' exists and is properly formatted, then a TINE server will read this file at initialization time and maintain histories of the designated properties. If a fec.xml file is use in lieu of .csv configuration files, then a 'HISTORY' tag with a 'PROPERTY' section can provide the same configuration information. Local histories with the default archiving parameters (5 minute short term depth, 1 month long term depth, 10% tolerance) can also easily be applied to a property during property registration by including the CA_HIST access flag. Another alternative is to instruct the server via the API call 'AppendHistoryInformation()' at initialization time. In any case, where property "<PROPERTY>" is keeping a local history, meta-properties such as "<PROPERTY>.HIST" (see Meta Properties) will be available to allow clients access to the local history data.
A 'history.csv' file (or a 'HISTORY' section within fec.xml) supports the following csv columns (or xml tags):
- "INDEX" provides a unique index which identifies 'this' local history record. This should be unique with respect to the entire FEC process (not just the equipment module).
- "LOCAL_NAME" gives the local equipment module name to which this history record refers.
- "PROPERTY" gives the calling property for which this local history is maintained.
- "DEVICE" gives the calling device for which this local history is maintained. Note that multi-channel arrays should be called as such, that is an array begining with a specific device name or number. Calls to the local history server for a specific device (i.e. channel) name will resolve which element of the multi-channel array is required.
- "DATA_LENGTH" gives the data size of the local history call.
- "FORMAT" gives the data format of the local history call.
- "HEARTBEAT" provides an archive 'heartbeat' in seconds, which effectively specifies the maximum time 'gap' between archived records on the long-term storage disk. Thus a value of 900 will ensure that, regardless of tolerance conditions, a value will be stored on the disk at least every 15 minutes (900 seconds).
- "POLLING_RATE" gives the calling interval (in milliseconds) which the local history subsystem should use in accessing the property to be archived. Note that the property can also be 'scheduled' at a faster rate.
- "ARCHIVE_RATE" gives the minimum archive interval and hence the minimum time 'gap' (in milliseconds) for which data should be archived on the local disk in long-term storage. A value of 1000 for instance will ensure that there is no more than 1 data record per second stored on the disk, regardless of any scheduling or other criteria.
- "TOLERANCE" provides a tolerance for archiving data to disk in long-term storage. This can either be given in percent (a number followed by '', e.g. '10') or as an absolute value (a number).
- "SHORT_DEPTH" gives the depth (array size) of the short-term storage. This is essentially the size of a ring buffer which holds the results of the calling parameters. The short term data will of course disappear when the server is restarted.
- "LONG_DEPTH" gives the depth (in months) of the long-term storage on the local disk. A value of 0 or less will NOT write data to the local disk, in which case the short-term storage is the only source of local history data.
- "FILTER" gives a filter to be used in committing archive data to disk or not. If the filter criterion is correctly parsed and resolves to a valid control system address then the associated readback value is used to determine whether storage conditions are valid or not. In the event of any error, conditions are assumed to always be valid. In other words, in order NOT to reject long-term storage a filter must be correctly parsed and correctly supply a readback value which does not fulfill the filter conditions. The filter string is parsed according to / <context>/<server>/<device>[<property>]<comparator>
where <comparator> is one of "=", "!=", ">", or "<".
An example of history.csv might be:
The relevant section within a fec.xml file will be embedded within the associated <PROPERTY> section as shown in:
A query to a TINE server for the extended property information for a particular property will reveal all aspects of the property, and in particular both the short term history depth (ring buffer size in main memory) and long term history depth (in months). If the server is not keeping a history of the property in question, then both of these numbers will be zero.
Many aspects of the local history server data follow the discussion above pertaining to the central archive server. History data acquisition from a client is identical to that of the central archive server, for instance. And for the same reasons, it is much better to keep a history record of a spectrum of monitors as opposed to each monitor individually. Filtering, on the other hand, exists only at the first two levels, namely the timestamp of the data must change and the data must itself change out of tolerance to be committed to disk (long-term storage). As to the short term ring buffer, data will be dutifully entered into the ring buffer at the archive polling rate if the timestamp changes and the call to the property from the local history server returns successfully.
In general, the same tools avaiable for retrieving central archive data are also available for retrieving local history data. Below is a snapshot of the local Windows history Viewer. Data retrieval can also be easily integrated into individual Windows applications by using the HistoryViewer.ocx ActiveX control.

The long term history data are stored on disk in the directory specified by the environment variable 'TINE_HISTORY_HOME'. If this variable is not set, then the history records are stored in the directory specified by the environment variable 'FEC_HOME'.
If this in turn is not set, then they are stored in the directory containing the server executable. The naming convention of the local history files follows that of the central archive server, namely 'arYYMMDD.<record number in hex>' where the record number is supplied either by the startup configuration file 'history.csv' or via the local history API call. As you might glean from the file name, the local history server maintains a new file every day, hence the last two characters in the file name refer to the day of the month (hard-wired to '01' in the case of the central archive server). Note that, by default, the local history files do NOT use 'minimal storage'. That is all records are stored with high resolution timestamps and associated data stamps (system stamp and user stamp). In this case (which is the default) the file names will begin with 'ta' (for tine archive) instead of 'ar'. If you go snooping about the TINE_HISTORY_HOME directory, you might also encounter files beginning with 'pi' (for 'points-of-interest' - see the discussion above).
A server's equipment module will then be called by the LHS at regular intervals.
The server nonetheless has a chance to distinguish a call made by the LHS if necessary by examining the 'access' parameter when the equipment module is called. If the call was made on behalf of the LHS, then the access parameter will contain the 'CA_HIST' bit.
The files maintained by the LHS are kept to the long-term storage depth specified by the configuration. This value is given in months and is in addition to the current month. That is, when this depth is specified as 1 month, then the LHS will only remove files older than the last month, etc. To prevent any long-term storage of data, this value should be specified as "-1" or "0".
If (due to limited disk space) the long term storage needs to be less than 1 month, then a specific number of days can be specified instead, as a 'fractional' part of a month. That is, specifying for example "0.5" as the long term depth will store only the last 5 days will be stored. If "0.16" is specified, then the last 16 days will be stored, etc.
Another method of controlling the amount of disk space used by the local history subsystem is to establish a 'minimum disk space'. This can be achieved via the API call SetMinimumDiskSpaceInBlocks() or by using the environment variable TINE_HISTORY_FREE_BLOCKS. If the local history subsystem noticed that there are fewer available bytes than given by this setting then the 'oldest' stored files will be discarded.
If any set of local history long term storage files are deemed 'special' and should be kept rather than removed once the long term depth has expired, then the relevant files should be identified (according to the file name rules described above) and moved or copied by hand into the 'archive saved path' directory. If this has not be specifically set via the SetHistoryStaticFilesRepository() API call, then it will be automatically assigned to a sub directory called 'SAVED' within the designated 'TINE_HISTORY_HOME' directory. For instance if 'TINE_HISTORY_HOME' points to "../HISTORY" (or if it has automatically been assigned if there is no specific setting) then the 'archive saved path' will be "../HISTORY/SAVED". You will have to create this directory if it does not already exist.
There is a caveat regarding the LHS and the long-term storage of data. Namely, if a client requests a massive amount of data (covering a large time range, for instance), this could tie up the server for several seconds depending on file system, disk fragmentation, etc. if the LHS is committing lots of data to disk on a fine time raster. If the server is build with the single-threaded TINE library and is blocked processing the history call, then it can't do anything else, such as commit more data to disk, or more important read its hardware! Under most circumstances, those servers keeping local histories should use the multi-threaded TINE library (which is the default in windows and java) in which case, calls to access data are made on a separate thread than the thread which is responsible for writing data to disk.
Other Viewers
A very useful tool in analyzing archive data is the Multi-Channel Analyzer.
This only has relevance for archived data sets which represent multi-channel arrays, but this includes a wide variety of data points, for instance beam orbits (an array of beam positions), beam loss monitors, vacuum pressures, temperature readouts, etc. Here all manners of navigating archived multi-channel data are offered, as shown in the images below:
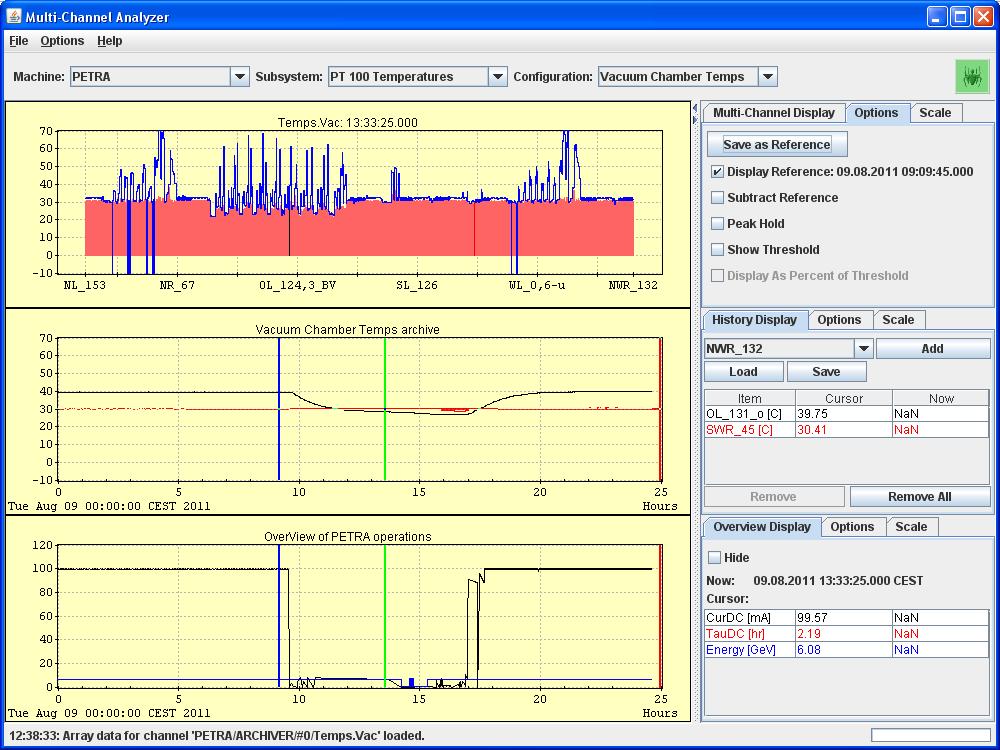
which shows the PT100 temperatures in the PETRA; and
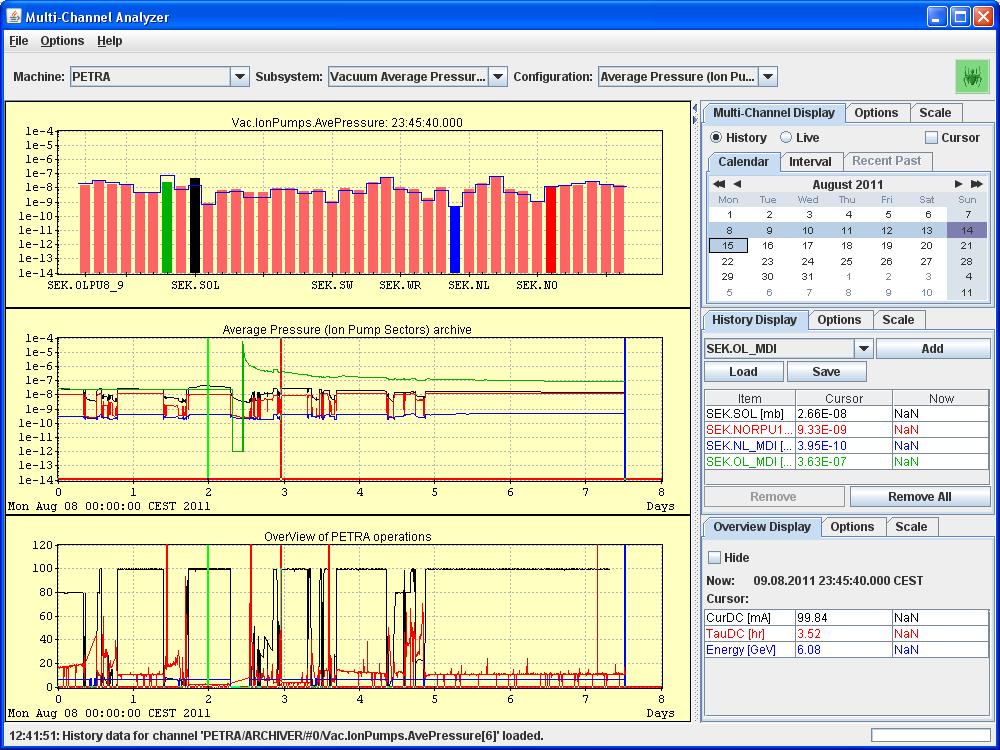
which shows The Petra Vacuum pressures.
In both cases above, history mode has been chosen over 'live mode' and a 'reference display' has been selected. This is shown as a blue polyline overlay on top of the displayed data. The time of the reference selection is likewise indicated on as a vertical bar in the trend charts.
Similarly, the time of the displayed multichannel data is displayed as a green bar in the trend charts. Such simple tools make it easy to investigate and correlate disturbances and problems.
The multi-channel analyzer is of course dedicated to examining multi-channel arrays. Another important category of data includes spectrum or 'trace' data sets. In addition to the general archive viewer and multi-channel analyzer, the generic Scope Trace Viewer is available for analysis of trace data.

Pre-defined Configurations
In the archive viewer, multi-channel analyzer, and scope trace viewers there are are generic browsing capabilities as well as pre-defined configurations which can present a coherent set of data at the click of a button. The contents of these pre-defined configurations are maintained at the central archive server. That is, these viewer applications will query the equipment name server to discover all archive servers and then query the selected archive server to ascertain which configurations there are. So there are several (optional) subdirectories found within the database directory which can be scanned by the archive server (the archive reader) to provide this information.
Under most (almost all) circumstances one should make use of the viewer configuration manager tools provided in the archive database manager as shown above! For the sake of completeness, we provide some examples below of the contents of these viewer configuration files maintained by the management tools.
Relevant to the archive viewer are the viewer configurations kept in the CONFIGS directory. Within this directory a single file called 'configs.csv' is scanned to determine which pre-defined configurations exists. An exmaple configs.csv is shown below:
Here one can see that several configurations are offered, the first having the descriptions "LINAC-2 Overview" and pointing to a description file 'OverViewL2.csv'. This is a more detailed .csv file containing the information the browser needs to know in order to display the contents. An example is shown below.
Local histories can also contain pre-defined configurations and even though the local history data is (by definition) not stored at the central archiver, these configurations are nonetheless maintained there. So also to be found in the CONFIGS directory is a single file called 'groups.csv', which specifies categories of local history subsystems which are to be offered by the archive viewer in local history sub-system browsing mode.
An example groups.csv file is shown below:
Here one sees that a group with description "DESY-2 RF" points to a 'file name' "RF". In this case "RF" refers to a sub directory RF, which should exist and if it does is scanned again for a file called 'configs.csv' in full analogy with the 'configs.csv' discussed above. Thus local history sub-system browsing will then offer (in this case) the "RF" and "Diag-Strom" categories and if one of these is selected, then the relevant configurations found in the configs.csv file are proposed. A single 'click' will load the entire configuration.
Thus the CONFIGS directory will contain many files, the principal files being 'configs.csv' and 'groups.csv'.
Parallel to the CONFIGS directory is another (optional) directory called MCA, which provides configurations for the multi-channel analyzer. Once again a 'configs.csv' file gives a list of descriptions versus file names. The configurations files are virtually the same as shown above for the case of the archive viewer configruations except that only the column headers "CONTEXT", "SERVER", "PROPERTY", and "DESCRIPTION" are scanned.
Finally, another parallel directory TRACE can optionally provide configurations for the scope trace viewer. Once again, a 'configs.csv' provides a list of configruation files and descriptions. In addition, a 'traces.csv' provides specific trace properties to offer as one-click displays for the generic scope trace viewer.
Setting Up the Archive Server
The download package will contain the servers 'march' and 'arcsrv'. In the windows download, these are already compiled and read to go; march.exe and arcsrv.exe found in tine\servers32\MARCH\bin and tine\servers32\ArchiveServer\bin respectively. In the other downloads (e.g. Linux) the 'makeall' script found in the tine/servers directory will make the binaries for you (provided tine has been installed properly). An example database is also provided in the tine/servers/MARCH/database directory. This is only a trivial example and a fully working example can be easily generated with the database manager utility. In any event, the 'march' process is the ARCHIVER server which will acquire data and write it to disk (as well as provide netmex-style repeater funtionality). This process should reside somewhere and have a a parallel directory the structure found in the 'database' subdirectory.
When the ARCHIVER process is running it will create its own repository in another parallel directory called 'DATA'.
Both processes need to run in parallel, sharing the same database and file repository. The setup tool 'setupArchiveServer' can be found in the tine/servers directory in the download package. This will create a common repository for a single pair of servers to be located under the 'root' directory given as input. For instance
setupArchiveServer C:\archiveServer
will produce the following file/directory structure on a windows system:
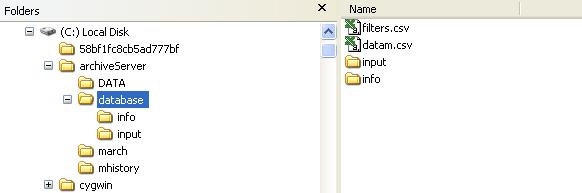
and
./setupArchiveServer ~/archiveServer
will produce a similar file/directory structure on a unix system, using symbolic links linking the DATA and database directory substructures for the 'mhistory' directory to those of the 'march' directory.
Note: this setup utility should be regarded as an example which may need to be 'tweaked' regarding the FECNAME used and the database name(s) used. Namely, the fecid.csv file in the download package contains the simple name "MARCH" as FEC Name for the march server and "HISTORY" as the FEC Name for the mhistory server. Likewise, the database name (entered in the 'startup.csv' file under march and in the 'database.csv' file under mhistory) contains the database file name 'datam.csv' A TINE site can and ofter will contain more than a single context and consequently more that a single archive server, each of which requiring a unique FEC Name. The database names can be identical if desired, but often also reflect the context to which they refer. Also note: the archive server can read multiple databases if desired. Thus the entries in either startup.csv or database.csv can be a (single column) list of database files.
Note: As seen above, the setup script does NOT create any optional subdirectories (such as CONFIGS or MCA) which might contain pre-defined configuration information. These must be added by hand when the need arises and the details are known.
Adding and Finding Records
Adding archive records to the local history subsystem can be achieved by configuration file at the server (see discussion of 'history.csv' or 'fec.xml'), or API call (see AppendHistoryInformation()), or 'on-the-fly' by making use of the "ADDHISTORY" stock property. Adding archive records to the central archive server is another matter. At the moment the addition and manament of central archive entries is entirely in the hands of the control system administrators and requires editing the archive database (presumeably via the database manager) and restarting the central archive server.
Note that the local history subsystem will NOT keep data on local storage beyond the configured long-term depth (in months) and will strive to remove the oldest data sets if the local disk capacity is near capacity. The central archive server is obligated to always keep the stored data, thus an admistrator should monitor the disk capacity of the central archive system and potentially move the oldest data sets to external disks or tapes when warrented. Under most circumstances, a large disk with proper filtering can hold many years of data on-line!
The central archive can (often does) re-register the property names originating at the server into something else. This is either of necessity or for 'cosmetic' reasons. The central archiver is a 'general' TINE server offering 'apples' and 'oranges' under a systematically known server name, namely "ARCHIVER" or "HISTORY" in the relevant context. So a property "Positions" might originate from a Beam Position Monitor server or a Collimator server, and therefore require some form of 'redecoration' at the central archiver. Likewise, poorly named properties (e.g. "ALL_DATA") can be remapped into something more meaningful at the archiver. In any event, a client program obtaining live data from a specific server might wish to display a trend of the data or otherwise access archived data from the central archiver, and the problem remains as to 'discover' under which name the same data is being stored there. This is of course, not a problem regarding the local history data (if available) as it is be definition stored under the same name there.
If the targeted server has specifically configured the reference back to the central archiver, then accessing the stock meta-property ".ARCH" will automatically redirect to the appropriate data set maintained there.
In any event, the archive server will keep a property alias for all registered archive properties according to the scheme '<server>.<property>', so that a call made in this fashion will automatically map to the correct data set. Thus, property "Positions" originating from server "Collimator" can be accessed as property "Collimator.Positions" at the servers "ARCHIVER" or "HISTORY".
The above has a couple of caveats. One: This can only work if the stored data paramter is a one-to-one representation of the acquired data set. This means that for instance if some property "ALL_DATA" must be split up into several data parameters, then there is no way to register an alias for those properties coming from the split! Two: TINE property names cannot exceed 64 characters in length, which is generally more than enough, but does not have to be true in general, if the originating property name is itself 64 characters long or the combination of server name and property exceeds this string size limit.
